[����������]ai������ʲô��˼��һҹ֮�䡰AI�����ˡ����ȫ�����ɴ������˴�Ҷ�ai��Ƶת�����ߵ����̽�֣�ai��������ʹ��GitHub�����һ����Դ��ĿSO-VITS-SVC�����������û������ڴ���Ŀ��ͨ��ai���ܹ����ռ������˵���ɫ���Ӷ�����Ŀ����ɫģ����������Ʒ��ai��������ô���ģ���֪�������ѸϽ���������
ai������ʲô��˼��һҹ֮�䡰AI�����ˡ����ȫ�����ɴ������˴�Ҷ�ai��Ƶת�����ߵ����̽�֣�ai��������ʹ��GitHub�����һ����Դ��ĿSO-VITS-SVC�����������û������ڴ���Ŀ��ͨ��ai���������ռ������˵���ɫ���Ӷ�����Ŀ����ɫģ����������Ʒ��ai��������ô���ģ���֪�������ѸϽ���������

ai������ʲô��˼
һҹ֮�䡰AI�����ˡ����ȫ������Bվ�ϣ�AI�����˷������ֿ��ܡ���˵�����ܶ���������Ԫǰ�������ס��ɶ����ȵȣ���һ�������������Ρ����ѱ�ʾ������һ����AI�����ˣ�����ȥ��......
��Щ������Ʒ����һ������so-vits-svc�Ŀ�Դ��Ŀ����ƾ������Ƶ���Ϳ���һ������ʽģ�����ϳ�Ŀ����ɫ����Ƶ��ѵ�����û���Ҫ����ѧģ�͡����ģ�Ϳ��Ա������ߺ�������Ҳ�����ò�ͬ��������������
ai���������أ���������ء�


ai����������
����һ��
һ��������
ѵ�����ݺܹؼ���Խ�����������Ƶ���ݣ�Ч��Խ�ã�����������һ��Сʱ���ϵ���Ƶ��
�Կ�����ʹ�� N �����Դ� 8G ���ϡ�
�ҽ���Ŀ����Ҫ�Ĵ��롢���������˳�����������Ҫ���������������Ի���ͨ���·�������ϵ�ҡ�
��Ȼ��Ҳ����ֱ���ÿ�Դ����ֱ�Ӳ��𣬵�ַ����
GitHub - svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion
����������װ
1.��װpytorch���ѧϰ���
��Ҫ��װpytorch,torchaudio,torchvision������
�ο���֮ǰд��https://yunlord.blog.csdn.net/article/details/129812705?spm=1001.2014.3001.5502
2.��װ�������
���Կ������ص���Ŀ�а�������requirements.txt����windowsΪ����
���뵽��Ŀ�У�ͨ��prompt��������ָ�
pip install -r requirements_win.txt
�������ݴ���
ѵ����Ƶ��������ҪԤ�⣬����˵ת������Ƶ������������ĸ��������仰˵��Ƶ�в��ܰ��������������ࡢ�����ȣ�����������ѵ����Ԥ�⣬����Ҫ�����ݽ��д�����
1.��ȡ����
���ǿ���ͨ��UVR5 �������ʵ�ְ������������롣
�� Windows �¿���ֱ��ʹ�á���������������������

���м��ɷ��������Ͱ��ࡣ
Ȼ���ٰ����������ã�ȥ��������
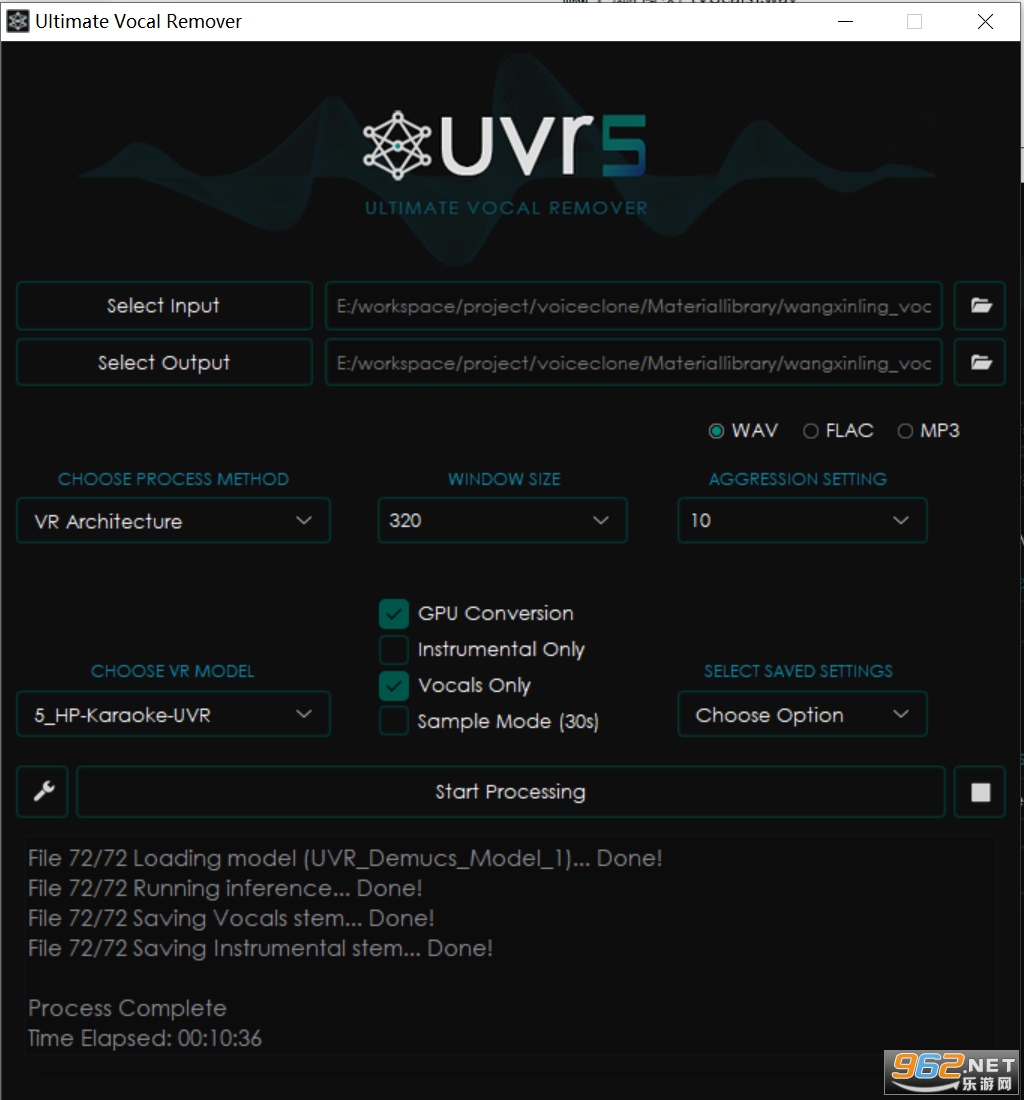
������ȡ���ĸɾ�������Ƶ�Ϳ�������ѵ����
2.�и���Ƶ
������Ϊ��Ƶ̫������Ҫ������ʮ�룬�����ױ��Դ棬��Ҫ����Ƶ�ļ�������Ƭ��
����ͨ�� Audio Slicer�������ʵ����Ƶ�з� ��
ֱ������ slicer-gui.exe��
��д����·������д���·��������������Ĭ�ϼ��ɣ������ͻ�õ��зֺõ���Ƶ�Ρ�

��������֮��������£���Ч�����õ�ɾ��������������Ƶ���������Ч�����á������������ʱ������30s�Ŀ���ͨ��д��python��Ƶ�и������н��С�
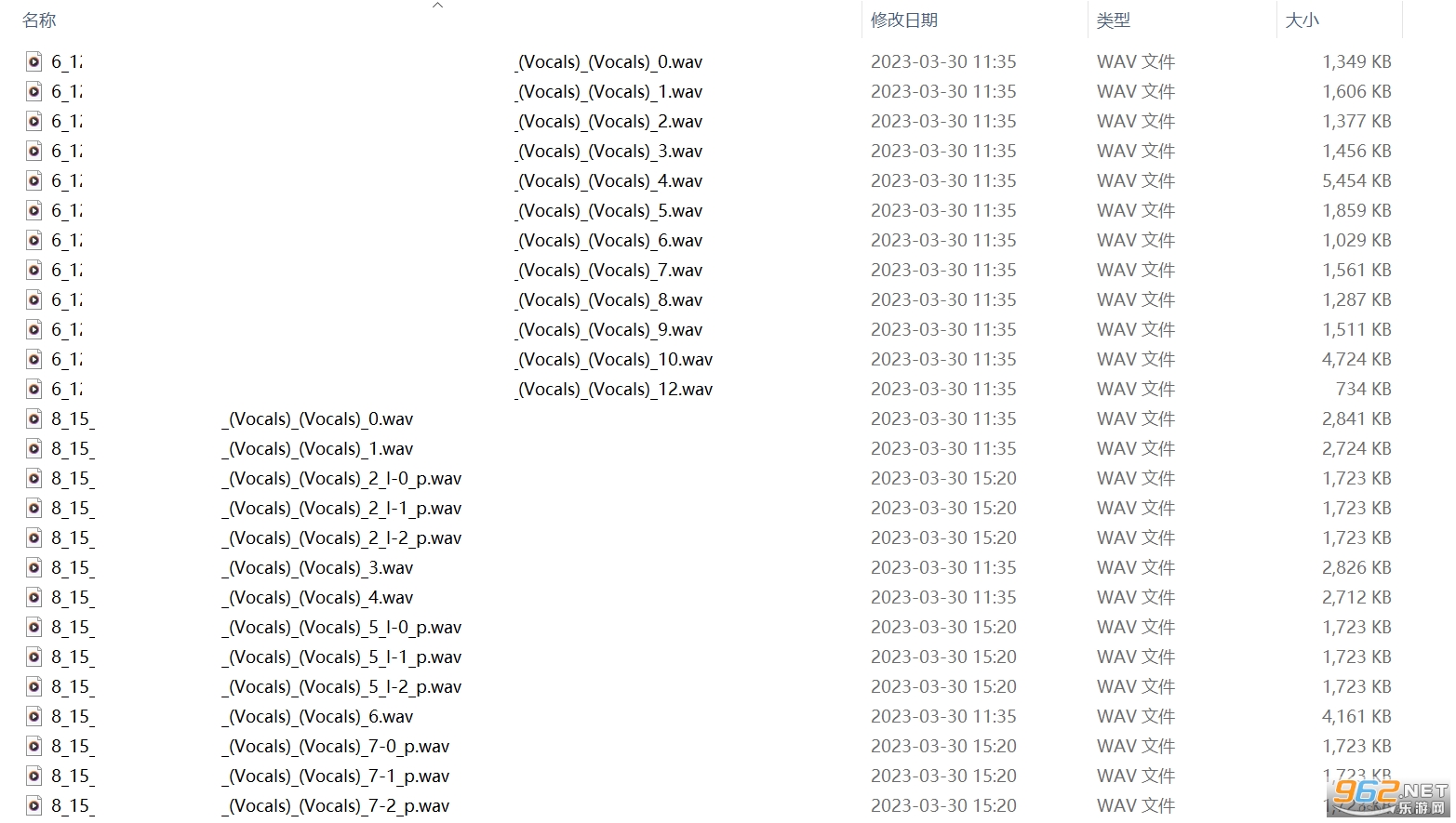
����Ŀ�� so-vits-svc-4.0/dataset_raw Ŀ¼�´���һ���ļ��У������ҵ��� wang_processed���������õ����ݷŵ����档
�ġ�ѵ��ģ��
��ѵ��ģ��ǰ��������Ҫ�º�ԭʼģ�ͣ�������ŵ���Ӧλ��
��checkpoint_best_legacy_500.pt����hubert�ļ�����
��D_0.pth��G_0.pth����logs/44kĿ¼��
1.����Ԥ����
����������ֱ��������Ŀ�����1.����Ԥ����.bat��
����ű����ǰ��ղ��裬���и��� py �ű�
�ز�����44100Hz������
python resample.py
�Զ�����ѵ��������֤�����Զ����������ļ�
python preprocess_flist_config.py
����hubert��f0
python preprocess_hubert_f0.py
������Ϻ���� datset/44k ������һ���ļ��С��������������ͼ��ʾ
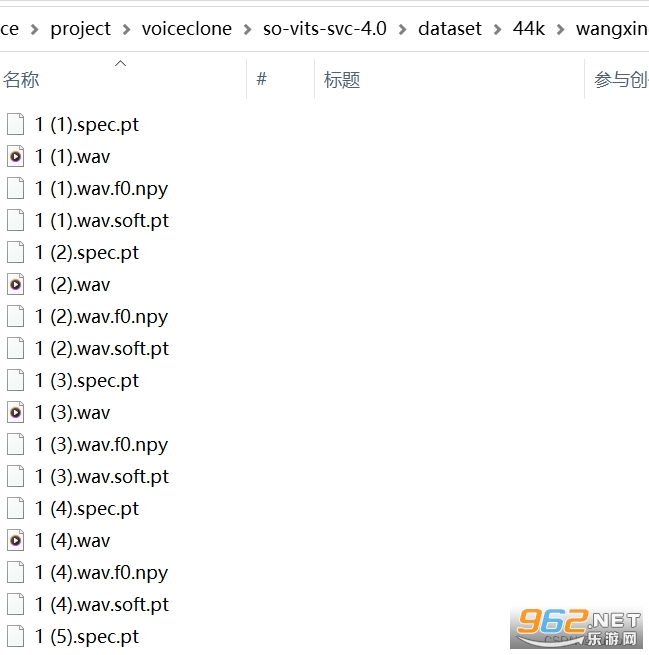
����ɾ�� dataset_raw �ļ����ˡ�
2.ģ��ѵ��
ֱ��������Ŀ�е�2.ѵ��.bat���ɿ���ѵ����
python train.py -c configs/config.json -m 44k
����Կ����ÿ������� batch_size ���ѵ���ٶȶ�Ӧ�������ļ��� configs/config.json �ļ��
���ѵ��ʱ��ܳ������˾���������ݽϺõĻ���ѵ����30000�����Ͼ���һ��������Ч����
3.����ģ��ѵ��
ֱ��������Ŀ�е�3.ѵ������ģ��.bat���ɿ���ѵ��������ȽϿ죬�����Ӽ������ꡣ
�����Ҫ�ǿ��Լ�С��ɫй©��ʹ��ģ��ѵ����������Ŀ�����ɫ������ʵ�����ر����ԣ����ǵ����ľ�����ή��ģ�͵�ҧ�֣���ڳݲ��壬��������ԣ���ģ�Ͳ������ںϵķ�ʽ���������Կ��ƾ������Ǿ������ռ�ȣ�Ҳ���ǿ����ֶ�����Ŀ����ɫ��ҧ������֮������������ҵ����ʵ����е㡣
ʹ�þ���ǰ������в��費�ý����κεı䶯��ֻ��Ҫ����ѵ��һ������ģ�ͣ���ȻЧ���Ƚ����ޣ���ѵ���ɱ�Ҳ�Ƚϵ͡�
ѵ�����̣�
ִ��python cluster/train_cluster.py��ģ�͵��������logs/44k/kmeans_10000.pt
�������̣�
inference_main.py��ָ��cluster_model_path
inference_main.py��ָ��cluster_infer_ratio��0Ϊ��ȫ��ʹ�þ��࣬1Ϊֻʹ�þ��࣬ͨ������0.5����
4.����Ԥ��
������
��һ��ĸ�������������������Ƶ�ز�������������ͨ��UVR5��ȡһ�β�����90s�ĸ����زġ�
��ģ����
�� app.py �����һ��
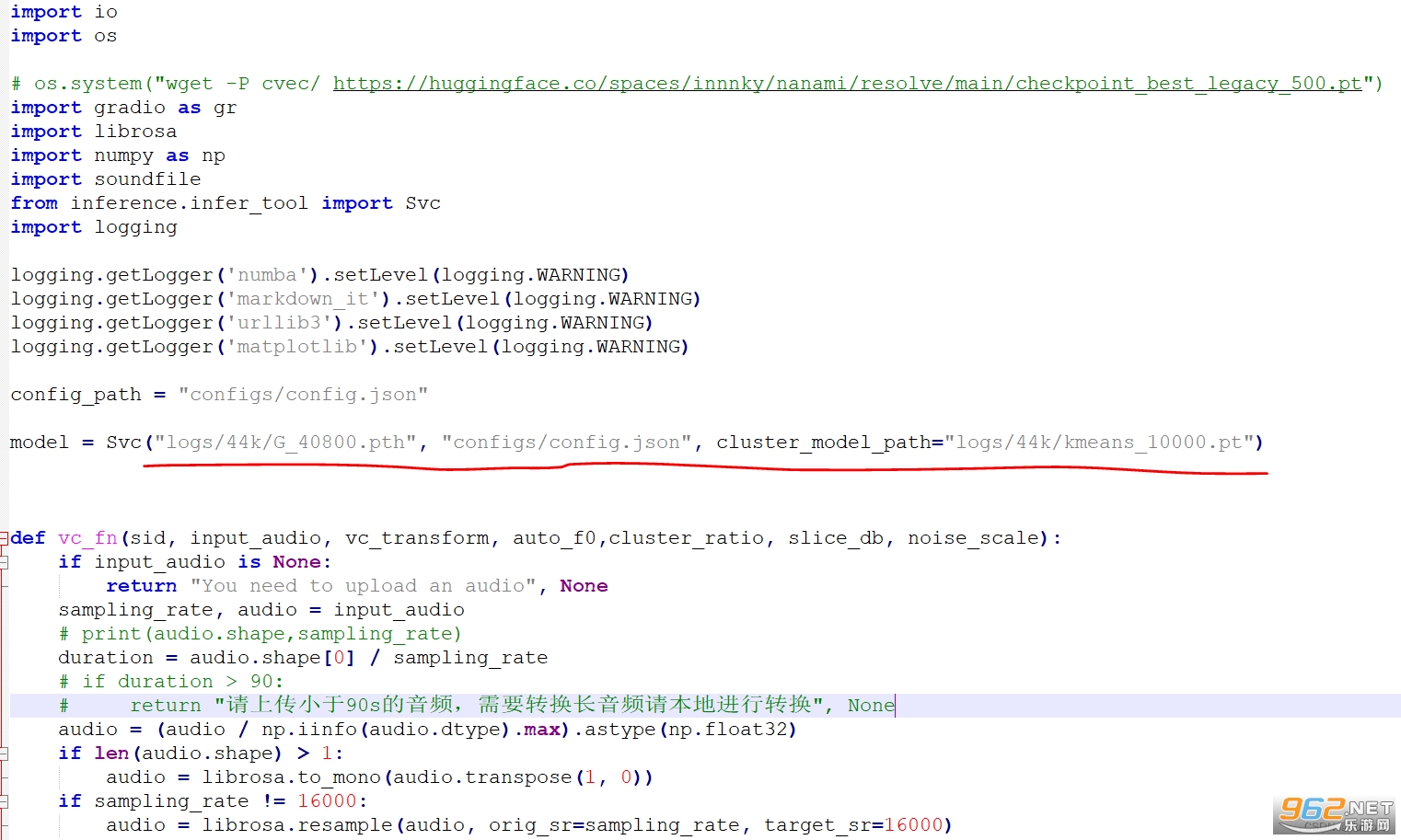
ѵ���õ�ģ�ʹ������ logs/44k Ŀ¼�������Ϊѵ���õ�ģ�͵�ַ���Լ���Ӧ�������ļ�������ǵ��������ɵ� pt �ļ�·����
����web
ֱ��������Ŀ�е�4.����Ԥ��.bat��
�����ֱ�ӿ���һ�� webui���������� url��ֱ�Ӹ��Ƶ��������ַ���д��ɡ�
����һ������ Web ҳ�棬����IJ���������ֱ��ʹ��Ĭ�ϵģ�����һ����Ƶ������ת����ɫ��
��������
����GitHub app���������½̳̽��в���
GitHub���أ���������ء�
github���Ժܷ���������Dz��뿪Դ��Ŀ�У��������Լ��Ĵ���.��ô,������ôȥ����һ����Դ��github��Ŀ�أ�
���ȣ�ȥ������Ҫ�����github��ҳ�������Fork�� => create Fork.

2. Ȼ�������Ͱ������Ŀ�����������Զ�ֿ̲⣬�����Լ����˺ŵ�¼�鿴��IJֿ⣬�ᷢ����IJֿ��Ѿ����������Ŀ�����Code,copy���github��ַ��һ��Ҫע�⣬Ҫ���Լ���github�˺��Ͻ��У���Ҫ����Ŀ���ߵIJֿ��ϣ���Ϊ��ľ��Ȩ��,���Dz��ܽ������ͺ��ĵ�.


3.��ͼ,��git����������git clone + copy��github��ַ�Ѳֿ��¡����Ĺ�������,
clone��ɺ���Ϳ�������Ĺ��������������Ŀ�ļ���Ȼ����Ϳ��Կ�ʼ�ɻ��ˣ�
�������Ȱ���Ĵ����ύ����IJֿ�����:
git add test.md;
gti commit -m something
git push origin��Զ�ֿ̲⣬ -u master�����ط�֧��
עpush ���� -u ���� ��Ϊ�������Զ�ֿ̲�����ı��ط�֧�������ӣ��Ժ�push��ʱ��Ϳ��Բ��ؼ������������.
Ȼ��������˺��½��� Pull requests������Ĵ�����
���ڶԷ��Ƿ������Ĵ��룬Ҫ���Է���������

 ϲ��
ϲ��  ��
��  ����
����  ��
��  ��
��  �ѹ�
�ѹ�
 airasia(com.airasia.mobile)app v12.6.0
�����н�ͨ / 24-05-24
airasia(com.airasia.mobile)app v12.6.0
�����н�ͨ / 24-05-24
 ��Ѳai�Ƽv1.3.2 �ٷ���
��ʵ�ù��� / 23-08-03
��Ѳai�Ƽv1.3.2 �ٷ���
��ʵ�ù��� / 23-08-03
 gencraft ai�滭 v1.1.1
��ʵ�ù��� / 23-05-08
gencraft ai�滭 v1.1.1
��ʵ�ù��� / 23-05-08
 �綯��ģ����Electric Trains0.809�汾v0.809 ���°�
���������� / 24-05-17
�綯��ģ����Electric Trains0.809�汾v0.809 ���°�
���������� / 24-05-17
 project sekaį���� v3.6.0
�������赸 / 24-05-27
project sekaį���� v3.6.0
�������赸 / 24-05-27
 cվ ai�滭��װ v1.0.2.6
��ʵ�ù��� / 23-10-23
cվ ai�滭��װ v1.0.2.6
��ʵ�ù��� / 23-10-23
��������
��������